Java语言中的“编译期”是一段“不确定”的操作过程。可能指的是以下三种:
前端编译器
把.java文件转变成.class文件的过程。
例如:Sun的javac、Eclipse JDT中的增量式编译器(ECJ)
后端编译器
把字节码转变成机器码的过程。
例如:JIT编译器(分为client和server端)
AOT编译器
直接把*.java文件编译成本地机器码的过程。
例如:GNU Compiler for the Java(GCJ)、Excelsior JET
编译器优化简介
前端编译器(Javac)在编译期的优化过程对于程序编码来说关系更密切。
后端编译器(JIT)在运行期的优化过程对于程序运行来说更重要。
虚拟机设计团队把对性能的优化集中到了后端编译器(JIT编译器)中,这样可以让那些不是由javac产生的Class文件(如JRuby、Groovy等语言的Class文件)也同样能享受到编译器优化所带来的好处。
但是Javac编译器做了许多针对Java语言编码过程的优化措施来改善程序员的编码风格和提高编码效率,Java的许多语法特性都是靠编译器的“语法糖”来实现的。
Javac编译器
Sun提供的Javac编译器的编译过程大致分为3个过程:
- 解析与填充符号表过程。
- 插入式注解处理器的注解处理过程。
- 分析与字节码生成过程。
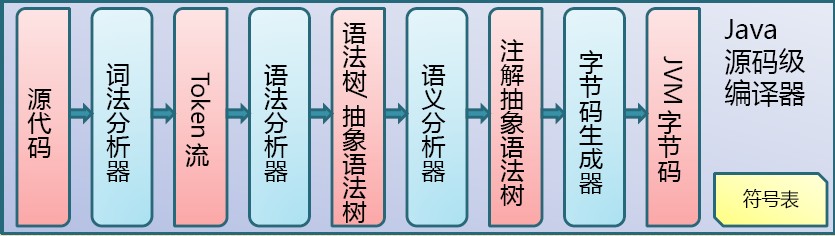
解析与填充符号表
词法分析
词法分析是将源代码的字符流转变为标记(Token)的集合。
单个字符是程序编写过程的最小元素;而标记(Token)则是编译过程的最小元素,关键字、变量名、运算符、字面量都可以称为标记。
语法分析
语法分析是根据Token序列构造抽象语法树的过程。
抽象语法树(Abstract Syntax Tree):是一种用来描述程序代码语法结构的树形表示方式。语法树中的每一个节点都代表着程序源代码中的一个语法结构(Construct),例如包、类型、修饰符、运算符、接口、返回值甚至代码注释都可以是一个语法结构。
经过语法分析后,编译器就不会再对源码文件进行操作了,之后的操作都是建立在抽象语法树之上。
填充符号表
符号表(Symbol Table):是由一组符号地址和符号信息构成的表格。
符号表中保存的信息在编译的不同阶段都要用到。在语义分析(后面的步骤)中,符号表所登记的内容将用于语义检查和产生中间代码,在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。
在这个阶段,如果类的代码中没有提供任何构造函数,编译器会添加一个没有参数的、访问性与当前类一致的默认构造函数。
注解处理器
在JDK 1.5之后,Java提供了对注解(Annotation)的支持,这些注解与普通的Java代码一样,是在运行期间发挥作用的。
在JDK 1.6中提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,可以把它看作是一组编译器的插件,可以读取、修改、添加抽象语法树中的任意元素。
注解处理器可以在处理注解期间对语法树进行修改,编译器将回到解析及填充符号表的过程进行重新处理,直到所有插入式注解处理器都没有再对语法树进行修改位置,每次循环称为一个Round。

语义分析与字节码生成
语义分析
语法分析得到了程序代码的抽象语法树表示,但无法保证源程序是符合逻辑的。
语义分析:主要任务是对结构上正确的源程序进行上下文有关性质的审查。
是否合乎语义逻辑必须限定在具体的语言与具体的上下文环境中才有意义。
例如:
后续赋值运算:
上述后续赋值如果在C语言中,都是可以正确编译的。
Javac的编译过程中,语义分析又分为标注检查与数据及控制流分析。
标注检查
标注检查,检查的内容包括诸如变量使用前是否已声明、变量与赋值之间的数据类型是否能够匹配等。
在标注检查步骤中,还有一个重要的动作称为常量折叠。
例如:在代码中定义了int a = 1 + 2;,在语法树上仍然能看到字面量1和2以及操作符+,但是经过常量折叠之后,她们将会被折叠为字面量3。
由于在编译期间进行了常量折叠,所以代码里面的
int a = 1 + 2比起直接定义int a = 3;,并不会增加程序运行期间的CPU指令运算量。
数据及控制流分析
数据及控制流分析:是对程序上下文逻辑更进一步的验证。它可以检查出诸如程序局部变量在使用前是否有赋值、方法的每条路径是否都有返回值、是否所有的受查异常都被正确处理了等问题。
编译期的数据及控制流分析与运行期类加载时的数据及控制流分析的目的基本上是一致的,但是校验范围有所区别。
例如:final语义校验
方法一与方法二在经过编译后得到的Class文件没有任何区别,局部变量与字段(实例变量、类变量)是有区别的,它在常量池中没有符号引用,自然就没有访问标志(Access_Flags)的信息,在Class文件中不可能知道一个局部变量是不是声明为final了。
因此,将局部变量声明为final,对运行期是没有影响的,变量的不变性仅仅由编译器在编译期间保障。
解语法糖
语法糖(Syntactic Sugar):是计算机语言中的某种语法,这种语法对语言功能没有任何影响,但是可以增加程序的可读性,方便程序员的使用。例如:泛型、变长参数、自动拆箱/装箱等。
解语法糖:虚拟机运行时不支持这些语法糖,在编译期间会将它们还原为简单的基础语法结构。
字节码生成
字节码生成阶会把前面各个步骤生成的信息(语法树、符号表)转换成字节码写到磁盘中,同时编译器还会进行少量的代码添加和转换工作(比如会添加实例构造器和类构造器,以及将字符串的加操作替换为StringBuffer或StringBuilder(JDK版本>=1.5)的append()操作等)。
实例构造器<init>()和类构造器<clinit>()
实例构造器<init>()和类构造器<clinit>()就是在字节码生成这个阶段被添加到语法树中的。(实例构造器和类构造器调用分别属于对象初始化和类初始化的两个过程,后面博客会继续介绍)
注意:这里的实例构造器并不是指构造函数,更不是默认的构造的构造函数,默认的构造函数添加是在填充符号表阶段。
这两个构造器的产生过程实际上是一个代码收敛的过程,编译器会把语句块、变量初始化、调用父类的实例构造器等操作收敛到<init>()和<clinit>()方法之中。
并且会保证执行顺序:先执行父类的实例构造器
init<>,然后初始化变量和执行语句块。
对于<init>()而言是非静态语句块{}块和实例变量,对于<clinit>()而言是静态语句块static{}块和类变量。<clinit>()无需调用父类的clinit()方法,虚拟机会保证父类构造器的执行(类加载)。
相关:Java 初始化顺序