|
|
ConcurrentHashMap相当于线程安全的HashMap,它继承于AbstractMap类,并实现了ConcurrentMap接口。
ConcurrentHashMap不允许key或value为null值。
ConcurrentHashMap、HashMap和HashTable
为什么要使用ConcurrentHashMap,而不是HashMap或者HashTable?
线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会导致HashMap中的Entry链表形成环形数据结构,从而使得在进行get等操作时引起死循环。效率低下的HashTable
HashTable使用synchronized来保证线程安全,但是在线程竞争激烈的情况下效率低下。因为HashTable会对整个表进行加锁来实现同步,而JDK 1.8中的ConcurrentHashMap则使用更细粒度的锁来实现同步(对表中的链表表头进行加锁)。
HashTable 虽然性能上不如 ConcurrentHashMap,但并不能完全被取代,两者的迭代器的一致性不同的,HashTable的迭代器是强一致性的,而ConcurrentHashMap是弱一致的。 ConcurrentHashMap的get,clear,iterator 都是弱一致性的。
原理和结构
JDK 1.8之前
JDK 1.8 之前的ConcurrentHashMap是通过锁分段来实现的,只有在同一个分段内才存在竞态关系。由Segment数组结构和HashEntry数组结构组成的。
一个ConcurrentHashMap里包含一个Segment数组,一个Segment里包含一个HashEntry数组。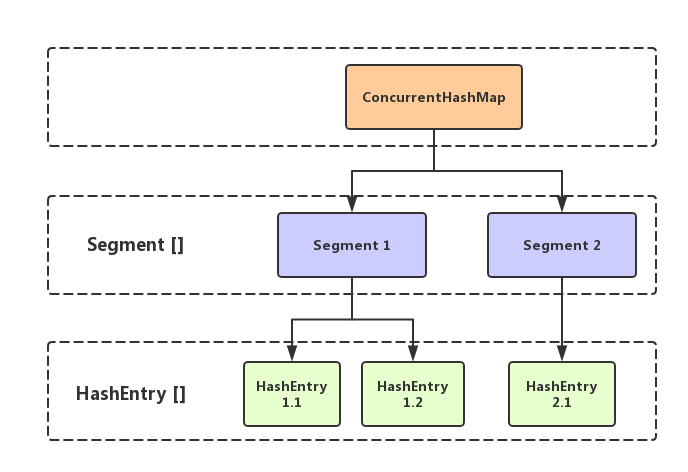
Segment是一个可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色。HashEntry用于存储键值,每个HashEntry是一个链表结构的元素。
每个Segment守护者一个HashEntry数组里面的元素,当对HashEntry数组里的数据进行修改时,必须首先获得与它对应的Segment锁。
Segment的结构和HashMap的结构类似,是一种数组和链表的结构。
JDK 1.8
JDK 1.8中,ConcurrentHashMap的实现已经抛弃了Segment分段锁机制,大量的利用了volatile,final,CAS等lock-free技术来减少锁竞争对于性能的影响。
CAS+Synchronized来保证并发更新的安全,底层依然采用数组+链表+红黑树的存储结构。但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
synchronized关键字锁住 table 中本次所操作对象的链表头。
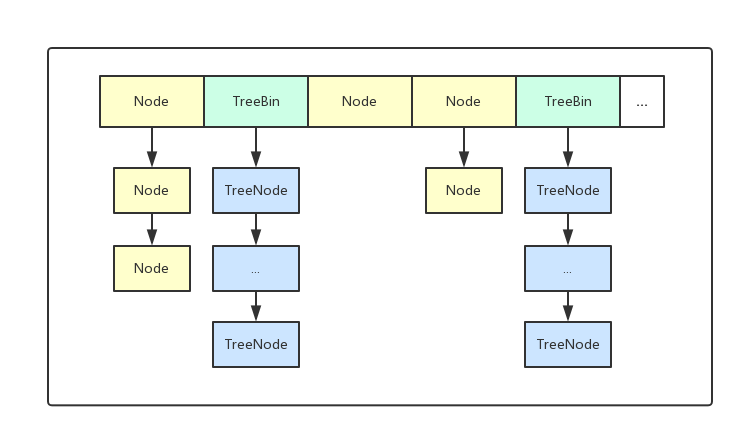
现在的实现中并没有用segment,而是延用 hashMap中单桶,定位到链表后,直接上锁,而后对链表就行操作,同样是将锁细化。
Segment虽保留,但已经简化属性,仅仅是为了兼容旧版本。
JDK 1.8实现
属性
|
|
sizeCtl
sizeCtl属性是个控制标识位:
- 0,默认初始值
- 负数,表示正在进行初始化或扩容操作控制标识符
- -1,表示正在初始化。
- -N,表示有N-1个线程正在进行扩容操作。
- 正数
- 如果table未初始化,表示table需要初始化的大小;
- 如果table初始化完成,表示下一次扩容的扩容阈值,默认是table大小的0.75倍。实际容量>=sizeCtl,则扩容。
内部类
Node
Node 是最核心的内部类,包装了key-value键值对。它和HashMap中的定义很相似,但是value和next属性设置为volatile,不允许调用setValue()方法直接改变Node的value域,增加了find()方法辅助map.get()方法。
TreeNode
当链表长度过长的时候,会转换为TreeNode。
但是与HashMap不相同的是,它并不是直接转换为红黑树,而是把这些结点包装成TreeNode放在TreeBin对象中,由TreeBin完成对红黑树的包装。
而且TreeNode在ConcurrentHashMap集成自Node类,而并非HashMap中的集成自LinkedHashMap.Entry<K,V>类,也就是说TreeNode带有next指针,这样做的目的是方便基于TreeBin的访问。
TreeBin
这个类并不负责包装用户的key、value信息,而是包装的很多TreeNode节点。它代替了TreeNode的根节点,也就是说在实际的ConcurrentHashMap“数组”中,存放的是TreeBin对象,而不是TreeNode对象,这是与HashMap的区别。另外这个类还带有了读写锁。
ForwardingNode
并不是我们传统的包含key-value的节点,只是一个标志节点,hash值为-1,并且指向nextTable,提供find方法而已。
只有table发生扩容的时候,ForwardingNode才会发挥作用,作为一个占位符放在table中表示当前节点为null或则已经被移动。
Unsafe和CAS
在ConcurrentHashMap中,随处可以看到U, 大量使用了U.compareAndSwapXXX的方法,这个方法是利用一个CAS算法实现无锁化的修改值的操作,它可以大大降低锁带来的性能消耗。
算法的基本思想就是:不断地去比较当前内存中的变量值与你指定的一个变量值是否相等,如果相等,则接受你指定的修改的值,否则拒绝你的操作。因为当前线程中的值已经不是最新的值,你的修改很可能会覆盖掉其他线程修改的结果。
unsafe静态块
|
|
三个原子操作
ConcurrentHashMap定义了三个原子操作,用于对指定位置的节点进行操作。正是这些原子操作保证了ConcurrentHashMap的线程安全。
构造方法
ConcurrentHashMap的构造方法仅仅是设置了一些参数而已。
而整个table的初始化是在向ConcurrentHashMap中插入元素的时候发生的。如调用put()、computeIfAbsent()、compute()、merge()等方法的时候,调用时机是检查table==null。
|
|
初始化initTable
初始化方法主要应用了关键属性sizeCtl,如果这个值〈0,表示其他线程正在进行初始化,就放弃这个操作。
在这也可以看出ConcurrentHashMap的初始化只能由一个线程完成。如果获得了初始化权限,就用CAS方法将sizeCtl置为-1,防止其他线程进入。初始化数组后,将sizeCtl的值改为0.75*n。
扩容transfer
transfer扩容操作:
1)单线程构建两倍容量的nextTable;
2)允许多线程复制原table元素到nextTable。
节点从table移动到nextTable,大体思想是遍历、复制的过程:
- 首先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素f,初始化一个forwardNode实例fwd。
- 如果f == null,则在table中的i位置放入fwd,这个过程是采用Unsafe.compareAndSwapObjectf方法实现的,很巧妙的实现了节点的并发移动。
- 如果f是链表的头节点,节点上锁(synchronized),就构造一个反序链表,把他们分别放在nextTable的i和i+n的位置上,移动完成,采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
- 如果f是TreeBin节点,节点上锁(synchronized),也做一个反序处理,并判断是否需要untreeify,把处理的结果分别放在nextTable的i和i+n的位置上,移动完成,同样采用Unsafe.putObjectVolatile方法给table原位置赋值fwd。
遍历过所有的节点以后就完成了复制工作,把table指向nextTable,并更新sizeCtl为新数组大小的0.75倍 ,扩容完成。
|
|
感谢:
http://www.importnew.com/22007.html
http://www.jianshu.com/p/c0642afe03e0
http://www.cnblogs.com/huaizuo/p/5413069.html