SQL优化的一般步骤
通过show status命令了解SQL执行频率
MySQL通过show [session|global] status命令可以提供服务器状态信息,默认是session(当前连接),global会显示自数据库上次启动至今。
eg: show status like 'Com_%';
Com_xxx表示每个xxx语句执行的次数,通常比较关心以下几个统计参数:
- Com_select
- Com_insert
- Com_update
- Com_delete
定位执行效率低地SQL语句
两种方式定位执行效率低的SQL语句:
- 通过慢查询日志定位,用
--log-show-queries[=file_name]选项启动时,mysqld写一个包含所有执行时间超过long_query_time秒的SQL语句的日志文件。 - 慢查询日志在查询结束以后才记录,可以使用
show processlist命令查看当前MySQL在进行的线程,包括线程的状态,是否锁表等,可以实时地查看SQL执行情况。
通过EXPLAIN分析低效的SQL的执行计划
通过EXPLAIN或DESC命令获取MySQL如何执行SELECT语句的信息,包括执行过程中表如何连接和连接的顺序。
eg: explain select sum(amount) from customer a, payment b where 1=1 and a.customer_id = b.customer_id and email = 'JANE.BENNETT@sakilacustomer.org'
得到相应的SQL执行计划如下: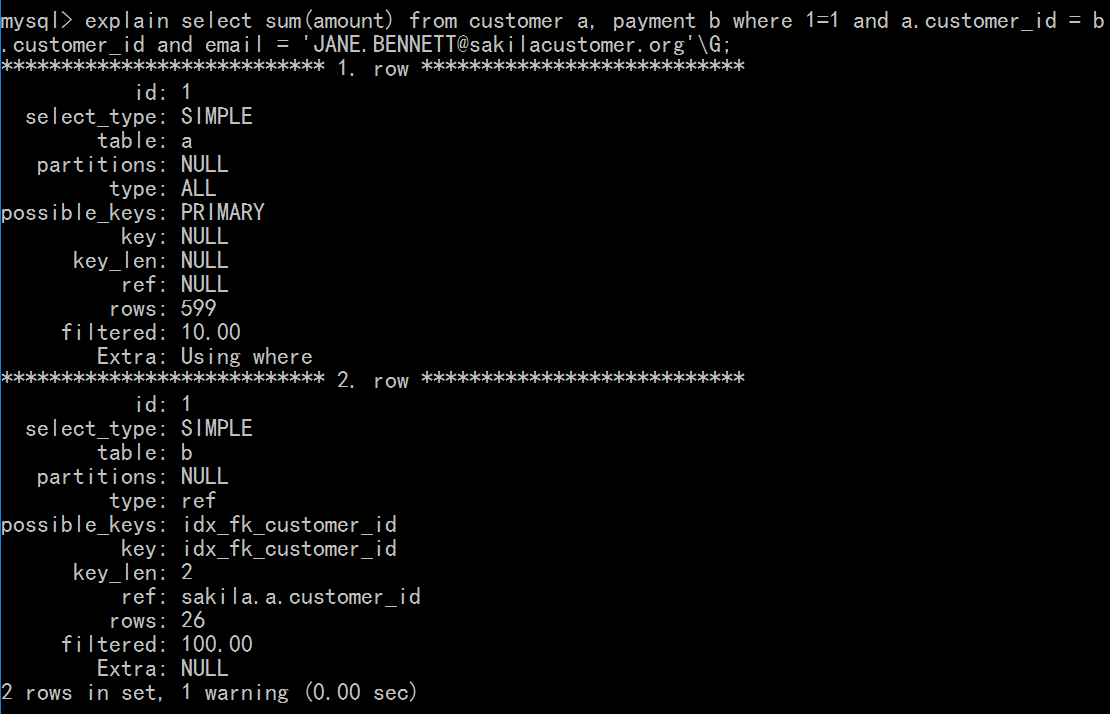
select_type: 表示SELECT的类型,常见的取值有SIMPLE(简单表,即不使用表连接或子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或后面的查询语句)、SUBQUERY(子查询中的第一个SELECT)。table: 输出结果集的表。type: 表示MySQL在表中找到所需行的方式,或者叫访问类型。性能由差到好:ALL(全表扫描) < index(索引全扫描) < range(索引范围扫描) < ref(使用非唯一索引或唯一索引的前缀扫描,返回匹配某个单独值的记录) < eq_ref(类似ref,区别是使用的索引是唯一索引) < const,system(单标中最多有一个匹配行) < NULL(MySQL不用访问表或索引就能得到结果)。possible_keys: 查询时可能使用的索引。key: 查询时实际使用的索引。key_len: 使用到索引字段的长度。rows: 扫描行的数量。
通过show profile分析SQL
MySQL从5.0.37版本开始增加了对show profiles和show profile的支持,用于查看执行过程中线程的每个状态和时间消耗。
通过have_profiling参数查看当前MySQL是否支持profile: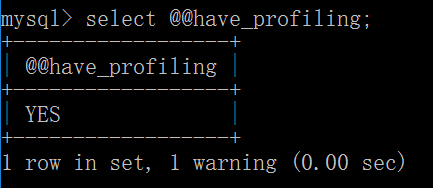
默认profiling是关闭的,可以通过set语句在Session级别开启profiling: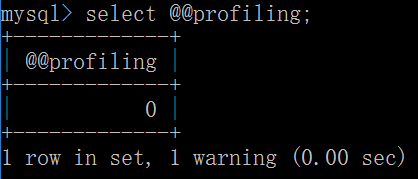

show profiles: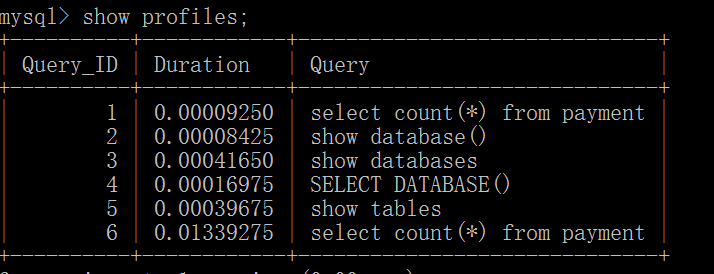
show profile for query 6: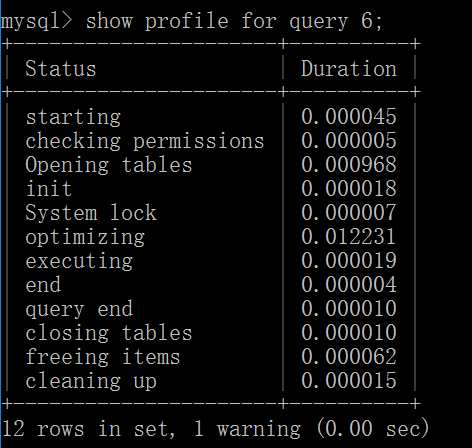
通过trace分析优化器如何选择执行计划
MySQL5.6提供了对SQL的跟踪trace,通过trace文件进一步了解为什么优化器选择A执行计划而不选择B执行计划。
使用方式:先打开trace,设置格式为JSON,设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整显示。
然后执行想trace的SQL语句,最后检查 INFORMATION_SCHEMA.OPTIMIZER_TRACE就可以知道MySQL是如何执行SQL的:SELECT * FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE\G
常见SQL优化
优化INSERT语句
- 如果从同一客户端插入很多行,应尽量使用多个值表的INSERT语句,这种方式可以大大缩减客户端与数据库之间的连接、关闭等消耗。
- 将索引文件和数据文件分在不同的磁盘上存放(建表中的选项)。
优化ORDER BY语句
MySQL的两种排序方式:
- 通过有序索引顺序扫描直接返回有序结果。
- 通过对返回数据进行排序,称为Filesort排序,所有不是通过索引直接返回排序结果的都是Filesort排序。Filesort排序是通过相应的排序算法,将取得的数据在 sort_buffer_size 系统变量设置的内存排序区中进行排序,如果内存装载不下,它就会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集。
优化目标:尽量减少额外排序,通过索引直接返回有序数据,WHERE和ORDER BY使用相同的索引,并且ORDER BY的顺序和索引顺序相同,并且ORDER BY的字段都是升序或降序。
优化GROUP BY语句
如果查询语句中显示包括一个包含相同列的ORDER BY子句,则对MySQL的实际执行性能没什么影响。
如果查询包括GROUP BY但用户想要避免排序结果的消耗,则可以执行ORDER BY NULL禁止排序。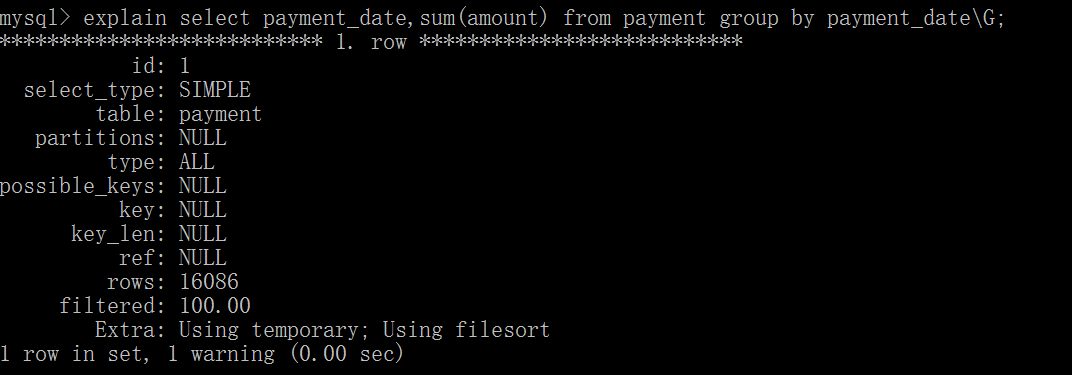
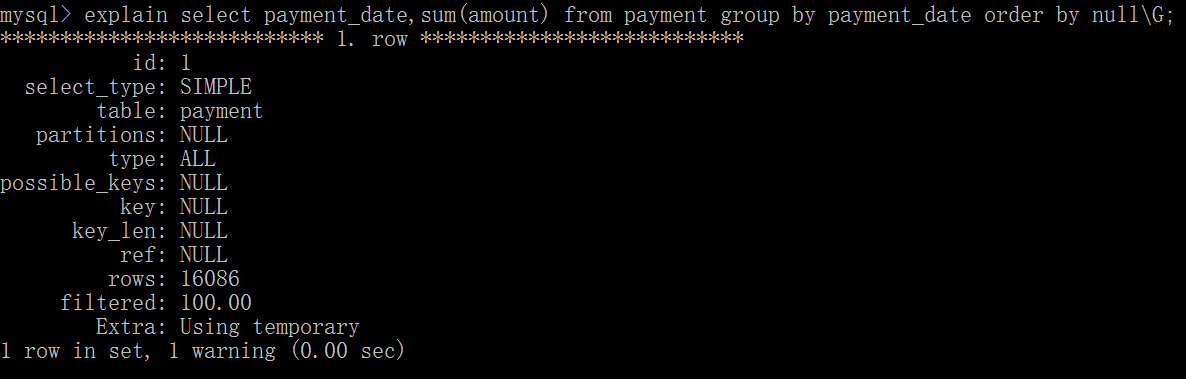
可以看出第一个语句需要进行“Filesort”,第二个不需要。
优化嵌套查询
有些情况下,子查询可以被更有效率的连接(JOIN)替代。
连接之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上需要两个的查询工作。
优化OR条件
对于含有OR的查询子句,如果要利用索引,则OR之间的每个条件列都必须用到索引;如果没有索引,则应该考虑增加索引。show index from table_1;查看表table_1的索引。
当OR之间的条件列都正确地用到了索引,并且从执行计划的描述(EXPLAIN)中,可以看到OR子句的查询实际是对OR各个字段分别查询后的结果进行了 UNION 操作。
如果在组合索引的列col1和col2上做OR操作时,则不会用到索引。
优化分页查询
索引上完成排序分页
在索引上完成排序分页的操作,最后根据主键关联回原表查询所需要的其他列内容。
例如,对电影表film根据标题title排序后取某一页的数据,直接查询的时候,explain输出结果中看到优化器实际上做了全表扫描,效率不高。
而按照索引分页后回表方式改写SQL后,已经不存在全表扫描了。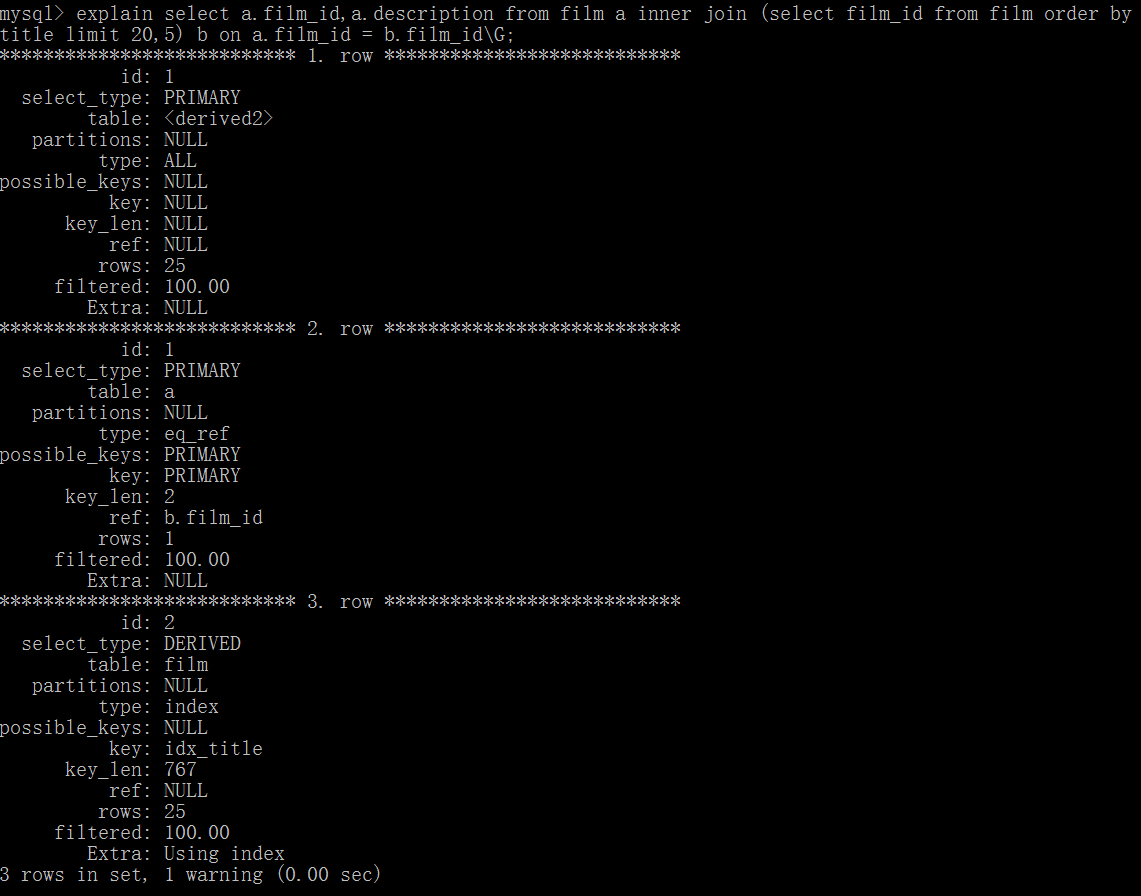
把LIMIT查询转换为位置查询
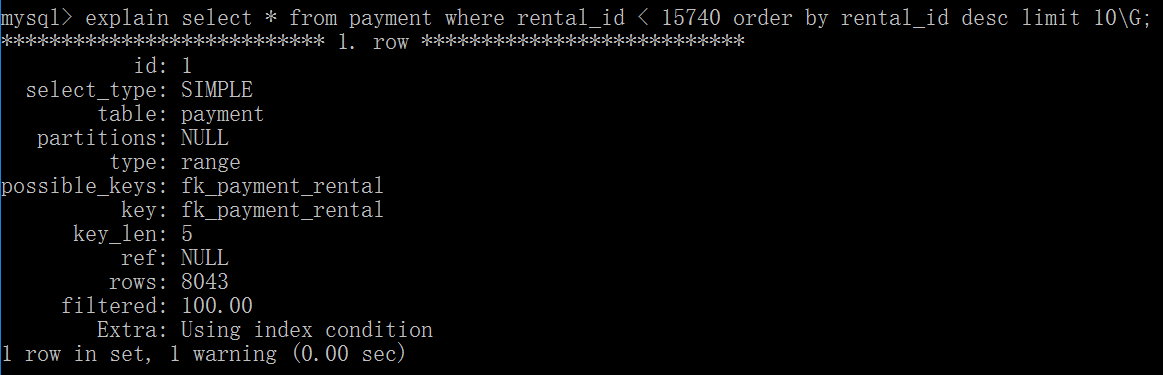
把LIMIT查询转换成位置查询,例如,假设每页10条数据,查询表payment中安rental_id逆序排序的第42页记录,能够看到执行计划进行了全表扫描。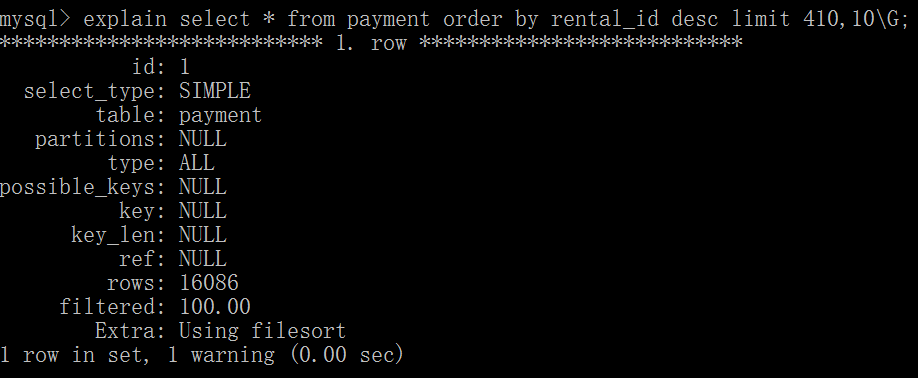
和开发人员协商一下,翻页的过程中通过增加一个参数 last_page_record,用来记录上一页最后一行的 rental_id,例如第41页最后一行的 rental_id=15640。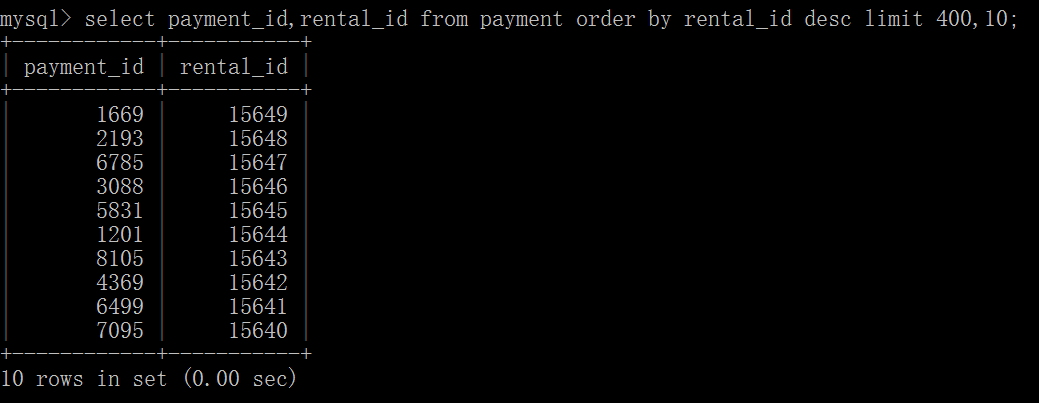
改写后的SQL为: