抓取优化设计方案
流程优化
将nutch默认的串行抓取流程改为并行抓取流程
串行流程介绍
nutch crawl流程图
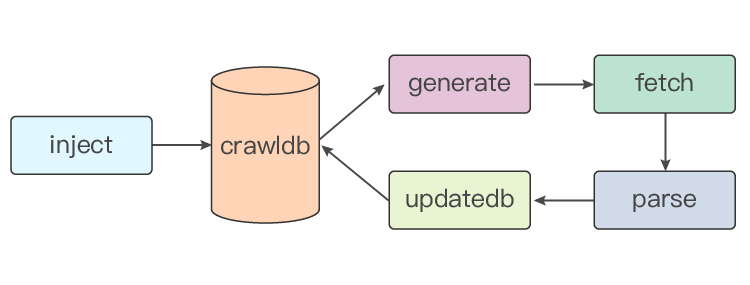
串行流程主要是这四个阶段:generate–>fetch–>parse–>updatedb,循环执行。
串行流程问题
当crawldb中数据量比较少时,fetch流程会占80%以上的时间,流程效率并不低。但是当crawldb中的url规模较大,例如百亿级别时,generate,parse和updatedb会占用大量时间,导致fetch流程的时间占比很低,甚至低于10%,极大地降低了抓取效率。从优化抓取量角度看,fetch流程应该在不断的运行。
并行流程
并发流程图
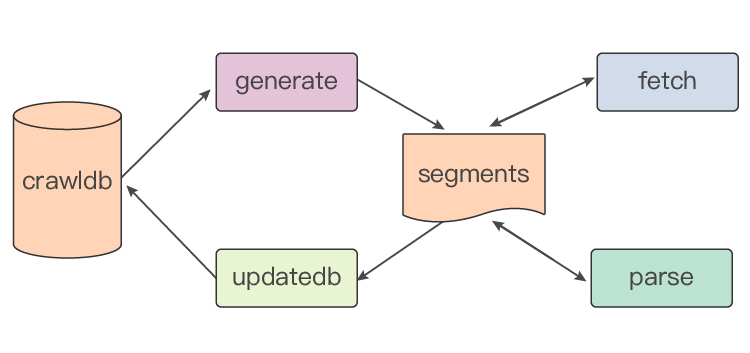
generate,fetch,parse,updatedb四个流程并行执行,基于segments中的tag标签进行同步。
标签
| 标签 | 说明 |
|---|---|
| tag_generate | 待抓取url生成成功,可以抓取了 |
| tag_fetching | 正在抓取 |
| tag_fetched | 抓取成功,可以解析 |
| tag_parsing | 正在解析 |
| tag_parsed | 解析成功,可以更新 |
| tag_updating | 正在更新 |
| tag_updated | 完成更新,当前segment完成基础抓取流程 |
generate优化
generate流程的主要功能是生成待抓取的url列表。由于generate需要对crawldb中所有的url打分、排序,在crawldb很大时,会占用大量的时间和资源。即使在并行流程下,generate也会成为瓶颈。
多组带抓取列表
为了充分利用generate流程对所有url进行打分,排序,在一次流程中生成多组待抓取列表,即多个segment。
crawldb更新
generate改成并行,同时一次生成多组segment时,需要对crawldb进行更新,避免待抓取url的重复。这一步会占用一定时间。
fetch优化
fetch流程的抓取模型是一个多线程抓取模型。nutch默认会将同一个站点分配到一个节点去抓,方便对站点抓取量进行控制,也对被抓取站点比较友好。
dns缓存
随着抓取规模增大,并发抓取的站点增多,会给dns解析服务造成很大压力,同时也会影响抓取性能。需要设计dns换粗,当前的dns缓存有两层,对于fetcher来说有一个local的map缓存和一个remote的redis换粗。
白名单
支持配置某些站点优先抓取。
并发抓取
支持配置某些站点在抓取的所有节点同时抓。
parse优化
当每天的抓取量在2亿以上时,parse也会占用很多资源。默认parse流程会用三种输出:外链,元信息,正文。外链用于updatedb流程,云信息用于link相关流程。正文部分在目前的抓取流程中不需要,可以省略。
updatedb优化
默认updatedb会将一个抓取完成的segment更新到crawldb。当crawldb在百亿规模时,遍历一次会比较费时。设置成一次更新多个segment,提高效率。
yarn队列优化
在并发的四个流程中,fetch流程是最优先的。为了优先保证fetch流程拥有抓取资源。将调度队列分为两种:prior和default。
| queue | capacity | max capacity |
|---|---|---|
| prior | 60% | 100% |
| default | 40% | 80% |
fetch在prior队列运行,其他流程在default队列运行,保证即使集群最忙时,fetch依然有20%的资源可以使用。
空间优化
随着抓取规模不断扩大,数据会占用更多的空间。要及时的将抓取中间数据删除,同时对有意义的数据结果进行压缩。
| 参数 | 值 |
|---|---|
| mapreduce.output.fileoutputformat.compress | true |
| mapreduce.output.fileoutputformat.compress.type | BLOCK |